Workloads
Workloads refer to specific applications or services that are deployed and managed within your cloud environment. A Workload exists within a particular Domain, and they encompass everything from the application code to the necessary infrastructure Resources a Workload depends on. Everything in Konfigurate exists to better facilitate the development, deployment, operations, and security of Workloads.
Workloads are not limited to applications or services. They can be all kinds of deployed artifacts like ETL or analytics pipelines, batch jobs, or machine learning models.
Workload YAML
Similar to Platforms and Domains, Workloads rely on GitOps and are defined using a declarative YAML configuration file which enables you to apply standard SDLC processes to your Workloads and their infrastructure Resources. Unlike Platforms and Domains, this configuration (referred to as the Workload YAML) sits alongside the Workload's application source code which lives in a Workload repository. This repository exists within a Domain subgroup in GitLab.
A Workload YAML is required for each of a Domain's Environments you wish to
deploy the Workload to. These Workload configuration files go in a special
deploy directory within the Workload repository, and the file name must match
the Environment's label. For example, if we have a dev Environment, we must
have a deploy/dev.yaml configuration to deploy the Workload to this
Environment.
Among other things, the Workload YAML specifies the Workload's runtime engine (e.g. Cloud Run or Kubernetes), runtime settings like CPU and memory, environment variables, triggers (e.g. a Cloud Pub/Sub subscription or Cloud Scheduler job), and the required infrastructure Resources like databases, storage buckets, and pub/sub topics.
Resources
The Control Plane automatically manages the provisioning of infrastructure Resources needed by a Workload. For example, if your application requires a Cloud SQL database or Cloud Storage bucket, these Resources are defined in the Workload YAML, and Konfigurate takes care of provisioning and managing them. Each Workload is also provisioned its own dedicated service account, and Konfigurate ensures a least-privilege security model by only giving the service account access to the Workload's Resources and nothing more. This prevents the possibility for overly permissive IAM. For services that do not support IAM-based authentication, such as databases, Konfigurate will provision credentials and store them in encrypted Secret Manager secrets which are only accessible to the Workload.
Rather than specifying complete Resource definitions, which can be quite complex, Workloads rely on Resource Templates to abstract Resource complexity from developers. The Workload YAML specifies a list of Resource claims which specify what Resources are required and which templates to use. Workloads within a Domain can share Resources, if a claim is made for the same Resource type and name, or a Workload can specify exclusive ownership over a Resource.
Resource Templates serve not just to abstract configuration complexity from developers but also provide a means to provide (or enforce) organizational defaults and standard Resource configurations. For example, a company may wish to ensure all production databases are configured in a high-availability mode and use customer-managed encryption keys. This is something that developers cannot override. However, the company defaults Resources to the us-central1 region, but this is something that can be changed by developers if needed. Resource Templates provide a way to implement these kinds of guardrails and sane defaults. Like everything else in Konfigurate, they are managed declaratively using GitOps. When combined with the governance primitives provided through Platforms and Domains, Resource Templates allow for an operations or platform team to provide a golden path—enforced standards for architecture, tech stack, and infrastructure configuration.
In addition to managing IAM, Konfigurate will also "autowire" Resource metadata into the Workload runtime using environment variables. For instance, Pub/Sub topic names, Cloud Storage bucket URLs, and Cloud SQL connection info is securely injected into the runtime (note that secrets, such as database user passwords, are never stored in the container but rather stored in Secret Manager with access governed through IAM).
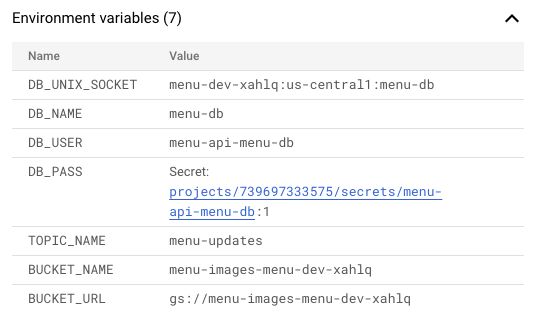
The Control Plane constantly reconciles Workloads and their Resources to ensure the desired state, as specified in the Workload YAML, matches the actual state of the world and corrects any configuration drift. When a Resource is modified or added, the Control Plane will automatically orchestrate and cascade dependencies. For example, if a Cloud SQL database is added to a Cloud Run-based Workload, Konfigurate will provision the database, then provision the database user, then create a Secret Manager secret containing the user password, then deploy a new revision of the Cloud Run service with the newly created database username and secret reference injected into the container.
See Resources for more information.
Runtimes
Workloads have an associated runtime which specifies how the Workload is executed. For example, we may want our Workload to run as a Cloud Run service or perhaps as a Dataflow job. See the example Workload YAML below, and refer to the Workload runtime spec for more details.
- Cloud Run
- Dataflow
apiVersion: konfig.realkinetic.com/v1alpha8
kind: Workload
metadata:
name: WORKLOAD_NAME
spec:
runtime:
apiVersion: run.cnrm.cloud.google.com/v1beta1
kind: RunService
metadata:
name: WORKLOAD_NAME
spec:
template:
containers:
- image: IMAGE_NAME
apiVersion: konfig.realkinetic.com/v1alpha8
kind: Workload
metadata:
name: WORKLOAD_NAME
spec:
runtime:
apiVersion: gcp.konfig.realkinetic.com/v1alpha8
kind: DataflowFlexTemplate
metadata:
name: WORKLOAD_NAME
spec:
image: IMAGE_NAME
metadata:
name: WORKLOAD_NAME
parameters:
- helpText: "The path and filename prefix for writing an output file. Example: gs://your-bucket/your-path"
label: Output destination
name: output
regexes:
- "^gs:\\/\\/[^\\n\\r]+$"
WORKLOAD_NAME and IMAGE_NAME are special placeholders in the Workload YAML
that the Konfigurate-provided CI/CD pipeline automatically replaces with the correct
values.
Triggers
Triggers provide a way to implement event- or cron-based invocations of a Workload. For example, with triggers we can configure a Cloud Pub/Sub push subscription which invokes a Cloud Run Workload whenever a message is received on a topic. Similarly, we could configure a Cloud Scheduler job to trigger the Workload on a schedule. See the example Workload YAML below, and refer to the Workload triggers spec for more details.
- Pub/Sub Subscription
apiVersion: konfig.realkinetic.com/v1alpha8
kind: Workload
metadata:
name: WORKLOAD_NAME
spec:
triggers:
- apiVersion: pubsub.cnrm.cloud.google.com/v1beta1
kind: PubSubSubscription
metadata:
name: subscription
spec:
ackDeadlineSeconds: 15
messageRetentionDuration: 86400s
retainAckedMessages: false
topicRef:
name: my-topic
runtime:
apiVersion: run.cnrm.cloud.google.com/v1beta1
kind: RunService
metadata:
name: WORKLOAD_NAME
spec:
template:
containers:
- image: WORKLOAD_IMAGE
Deployment
Workloads are deployed using GitOps by applying the Workload YAML to the Control Plane. Konfigurate provides an out-of-the-box CI/CD pipeline configuration for GitLab which implements a trunk-based development model. By default, the Workload is deployed to the dev environment on commits to main, to the stage environment on a manual action, and to prod on a tagged release. This is provided through GitLab project templates. However, you can implement your own pipelines with custom behavior if desired.
Workload repositories are only able to deploy to the Control Plane namespace for the Domain containing the Workload. This creates a strong isolation and security boundary between Domains. This is configured and managed automatically by the Control Plane when a Domain is created.
We encourage using the Konfigurate-provided Workload templates which set up a functioning Workload repository structure and CI/CD pipeline. When a new project is set up using a Workload template, it can be immediately deployed to a Domain Environment with no changes by simply running the GitLab pipeline. To do this, go to Build > Pipelines > Run pipeline and click Run pipeline on the main branch. This will start the Workload pipeline which will build the container image, push the image to the Domain's dev Environment registry, and deploy the Workload to the dev Environment.
This deployment-first approach is something we call Deployment-Driven Development. The idea is to start deploying new applications to a real environment from day one rather than waiting later in the development process. For some organizations, getting a workload to an actual environment can take just as long as building the application itself. Deployment-Driven Development shifts this left by starting with a fully functioning, deployed application and then working our way backwards.
Create a Workload
Workloads are created by creating a new project in the respective Domain subgroup in GitLab. The easiest way to do this is to use the Konfigurate-provided Workload project templates which set up a fully functioning Workload and CI/CD pipeline.
Below is an example demonstrating how to create a Workload which uses the Cloud
Run runtime engine, sets CPU, memory, and scaling limits, and has a Cloud SQL
database, Pub/Sub topic, and Cloud Storage bucket. Note that WORKLOAD_NAME
and WORKLOAD_IMAGE are placeholders value that Konfigurate will automatically set.
Refer to the Workload spec for the complete set of Workload configurations.
- YAML
- Konfigurate UI
- GitLab
You can create a Workload by applying the YAML definition to the Control Plane from a Workload repository.
apiVersion: konfig.realkinetic.com/v1alpha8
kind: Workload
metadata:
name: WORKLOAD_NAME
spec:
runtime:
apiVersion: run.cnrm.cloud.google.com/v1beta1
kind: RunService
metadata:
name: WORKLOAD_NAME
spec:
template:
containers:
- image: WORKLOAD_IMAGE
resources:
limits:
cpu: "1"
memory: 512Mi
scaling:
maxInstanceCount: 10
resources:
- apiVersion: sql.cnrm.cloud.google.com/v1beta1
kind: SQLInstance
metadata:
name: menu-db
- apiVersion: pubsub.cnrm.cloud.google.com/v1beta1
kind: PubSubTopic
metadata:
name: menu-updates
- apiVersion: storage.cnrm.cloud.google.com/v1beta1
kind: StorageBucket
metadata:
name: menu-images
- Navigate to the homepage of the Konfigurate UI.
- Navigate to the Platform containing the Domain you want to create the Workload within by clicking the Platform in either the side navigation or in the main viewport.
- Navigate to the Domain you want to create the Workload within by clicking the Domain in either the side navigation or in the main viewport.
- Click the + WORKLOAD button. This will open the Create from template screen within the Domain in GitLab.
- In the Create from template screen, click the Group tab.
- Locate the Konfigurate Workload template you wish to use and click the Use template button.
- Enter your Workload information.
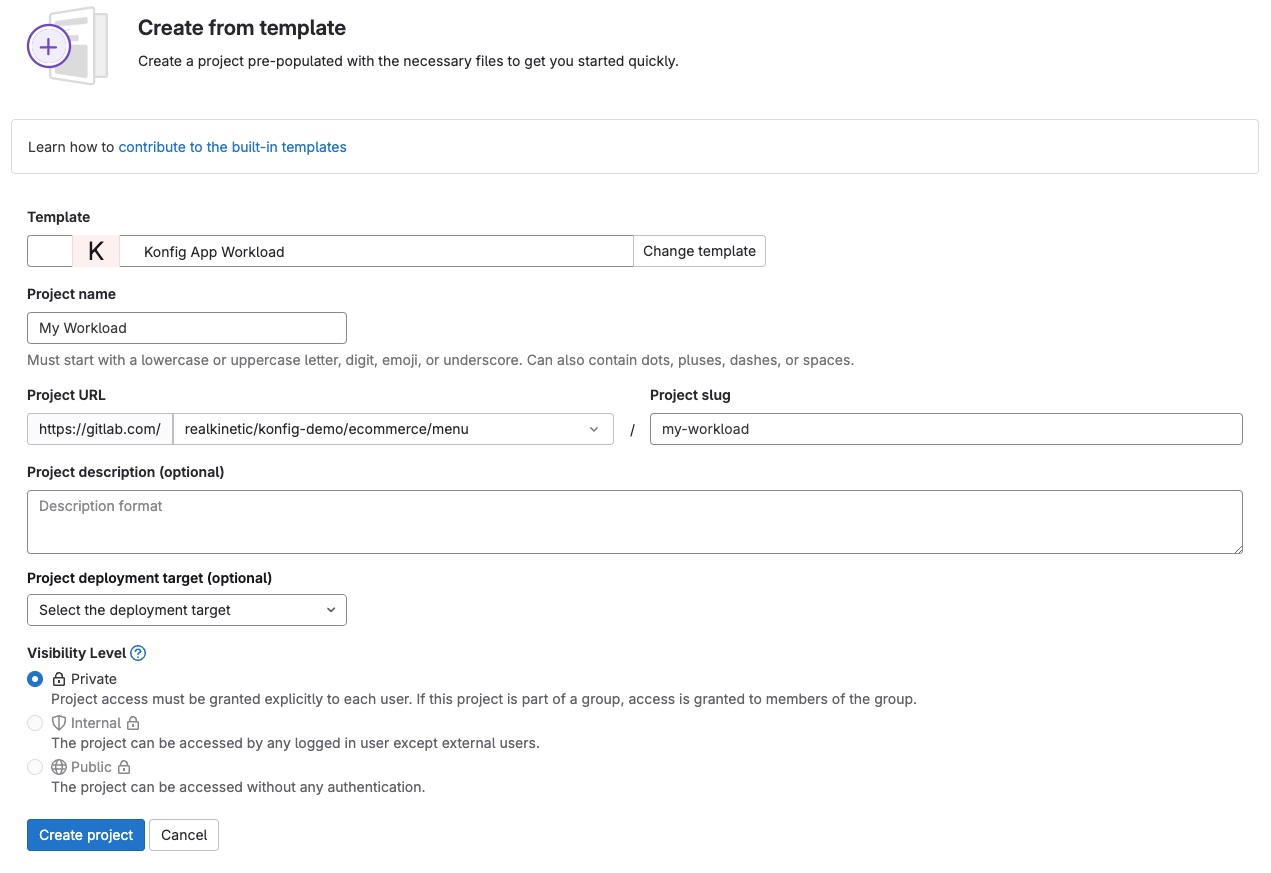
- Click Create project.
- This will create a new Workload project in the Domain subgroup containing
a basic Dockerfile, fully functioning .gitlab-ci.yml, and a
deploydirectory containing adev.yamlWorkload configuration. The Workload will not appear in the Control Plane (either in the Konfigurate UI or Konfigurate CLI) until the Workload has been deployed to an Environment by running the CI/CD pipeline.
- Navigate to the Control Plane subgroup in GitLab.
- Navigate to the Platform subgroup containing the Domain you want to create the Workload within by clicking the Platform in the Subgroups and projects list or expanding the Platform by clicking the arrow.
- Navigate to the subgroup for the Domain you want to create the Workload within by clicking the Domain in the Subgroups and projects list.
- Click the New project button.
- Click Create from template.
- In the Create from template screen, click the Group tab.
- Locate the Konfigurate Workload template you wish to use and click the Use template button.
- Enter your Workload information.
- Click Create project.
- This will create a new Workload project in the Domain subgroup containing
a basic Dockerfile, fully functioning .gitlab-ci.yml, and a
deploydirectory containing adev.yamlWorkload configuration. The Workload will not appear in the Control Plane (either in the Konfigurate UI or Konfigurate CLI) until the Workload has been deployed to an Environment by running the CI/CD pipeline.
List Workloads
The deployed Workloads within a Domain Environment can be viewed either with the Konfigurate UI or Konfigurate CLI.
- Konfigurate UI
- Konfigurate CLI
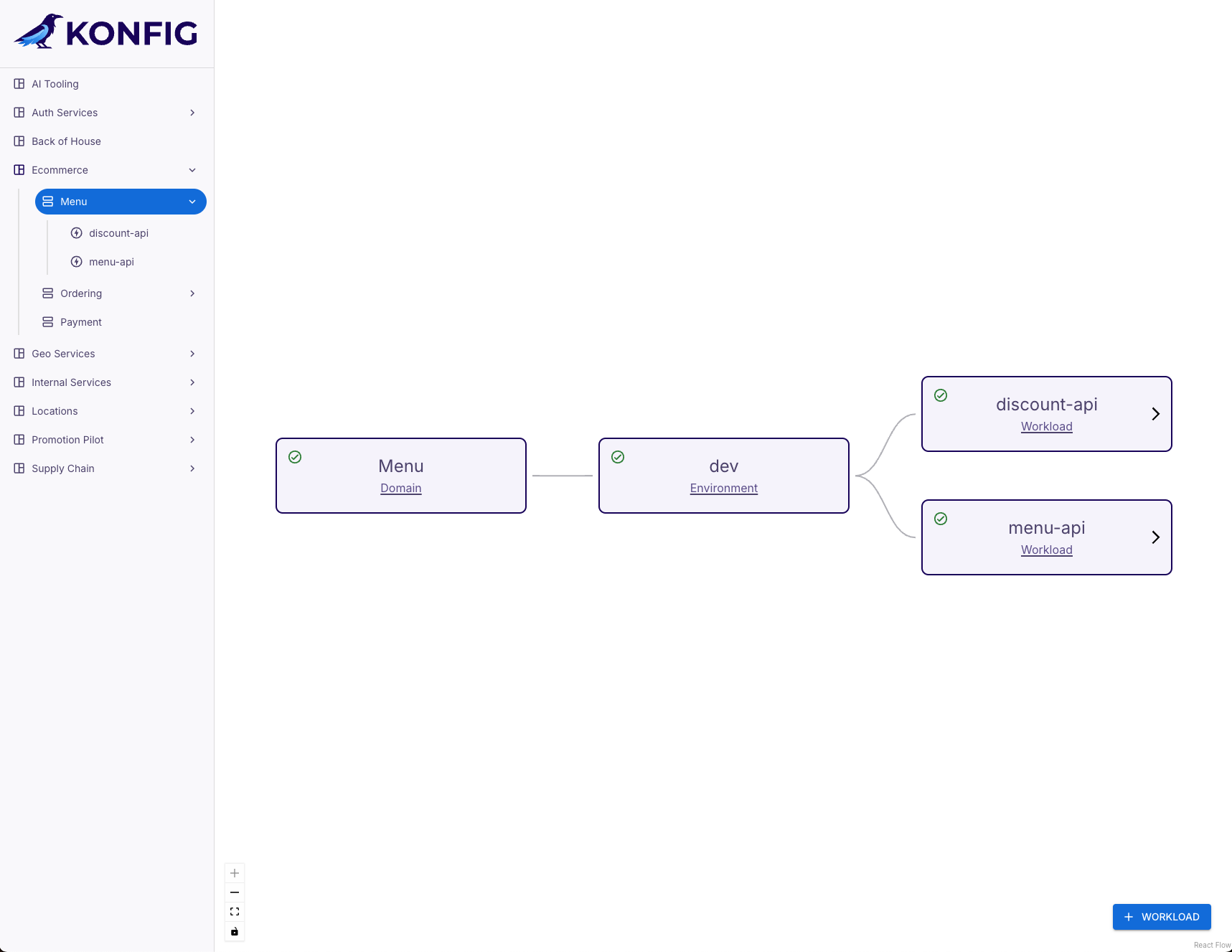
- Navigate to the homepage of the Konfigurate UI.
- Navigate to the Platform containing the Domain you want to view Workloads for by clicking the Platform in either the side navigation or in the main viewport.
- Navigate to the Domain you want to view Workloads for by clicking the Domain in either the side navigation or in the main viewport.
- Workloads will be displayed in both the side navigation and in the main viewport for all Environments.
- Ensure the Konfigurate CLI is installed and initialized.
- Run the
konfig workloads listcommand:
konfig workloads list -e [ENVIRONMENT] [PLATFORM ID] [DOMAIN ID]
The response looks like the following example:
ID CREATED RUNTIME RESOURCES READY
discount-api 2024-08-12 19:30:46 +0000 UTC RunService 1 TRUE
menu-api 2024-08-12 19:52:48 +0000 UTC RunService 3 TRUE
Get Workload Details
Metadata for a Workload can be retrieved either with the Konfigurate UI or Konfigurate CLI.
- Konfigurate UI
- Konfigurate CLI
- Navigate to the homepage of the Konfigurate UI.
- Navigate to the Platform containing the Domain you want to view the Workload for by clicking the Platform in either the side navigation or in the main viewport.
- Navigate to the Domain containing the Workload you want to view by clicking the Domain in either the side navigation or in the main viewport.
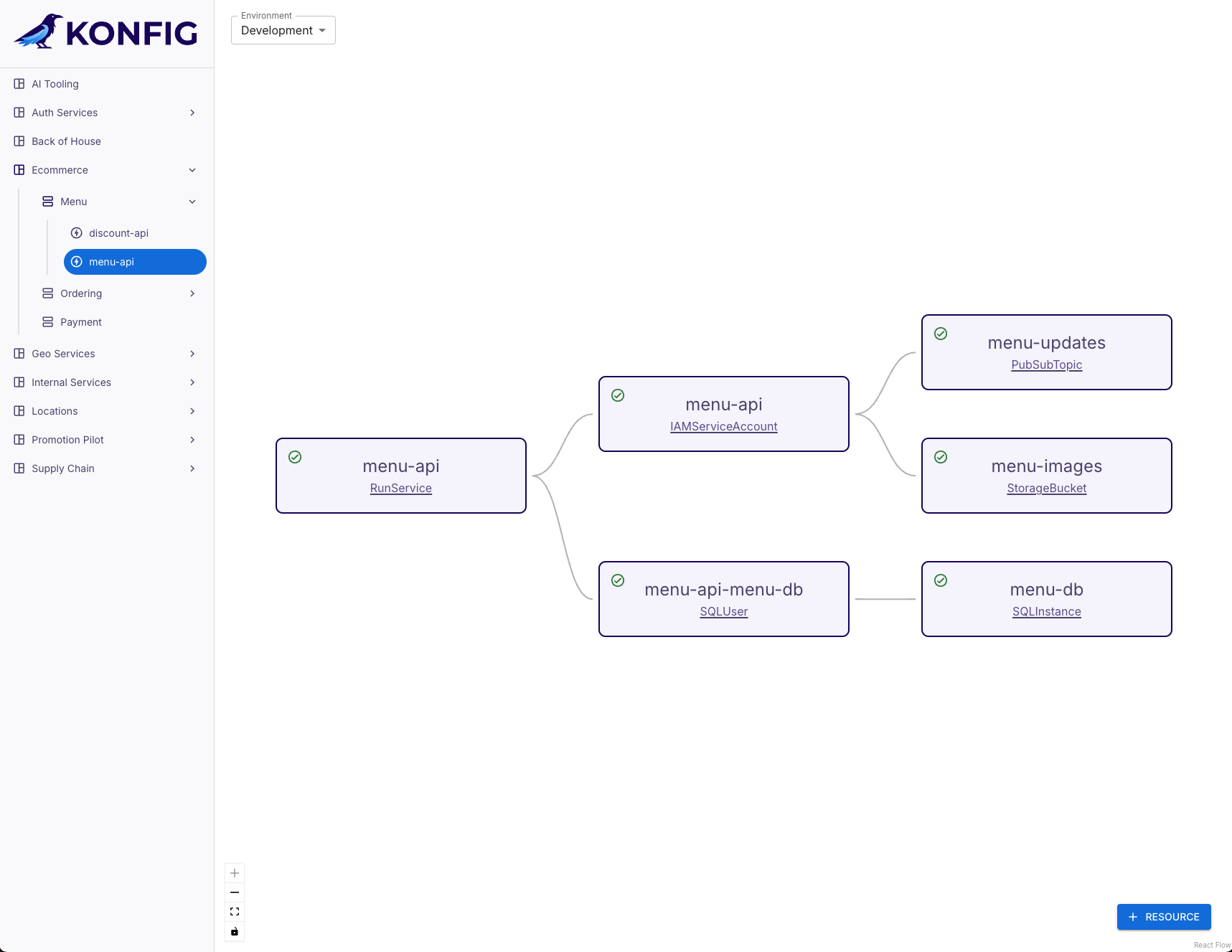
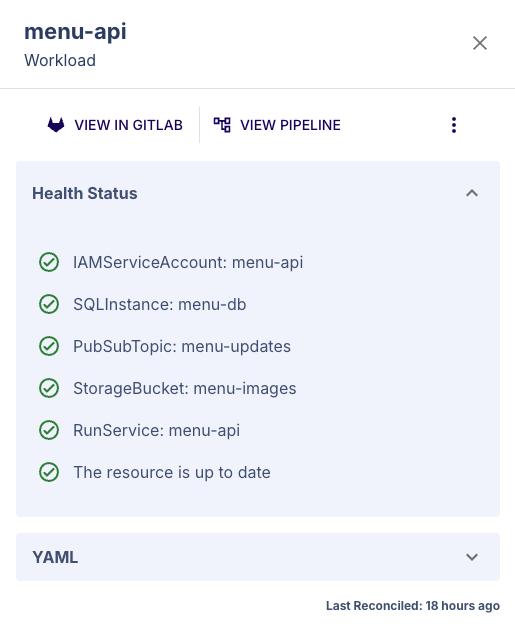
- Locate the desired Workload in the main viewport and click the status icon.
- This will expand a sidebar containing information about the Workload such as links to the Workload in GitLab and its source definition, the Workload status, and the Workload's YAML applied to the Control Plane.
- Ensure the Konfigurate CLI is installed and initialized.
- Run the
konfig workloads describecommand:
konfig workloads describe -e [ENVIRONMENT] [PLATFORM ID] [DOMAIN ID] [WORKLOAD ID]
The response looks like the following example:
apiVersion: konfig.realkinetic.com/v1alpha8
kind: Workload
metadata:
name: menu-api
creationTimestamp: 2024-08-12T19:52:48Z
spec:
resources:
- apiVersion: sql.cnrm.cloud.google.com/v1beta1
kind: SQLInstance
metadata:
name: menu-db
- apiVersion: pubsub.cnrm.cloud.google.com/v1beta1
kind: PubSubTopic
metadata:
name: menu-updates
- apiVersion: storage.cnrm.cloud.google.com/v1beta1
kind: StorageBucket
metadata:
name: menu-images-123456
runtime:
apiVersion: run.cnrm.cloud.google.com/v1beta1
kind: RunService
metadata:
name: menu-api
spec:
template:
containers:
- image: us-central1-docker.pkg.dev/menu-dev-xahlq/docker/menu-api:3b9716c69ae771bf8fedcdeac8192292f4b7e4d4
resources:
limits:
cpu: "1"
memory: 512Mi
scaling:
maxInstanceCount: 10
status:
conditions:
- lastTransitionTime: 2024-08-12T19:52:58.908929Z
lastUpdateTime: 0001-01-01T00:00:00Z
message: 'IAMServiceAccount: menu-api'
reason: Ready
status: "True"
type: IAMServiceAccount:menu-api
- lastTransitionTime: 2024-08-12T19:52:58.909008Z
lastUpdateTime: 0001-01-01T00:00:00Z
message: 'SQLInstance: menu-db'
reason: Ready
status: "True"
type: SQLInstance:menu-db
- lastTransitionTime: 2024-08-12T19:52:58.909076Z
lastUpdateTime: 0001-01-01T00:00:00Z
message: 'PubSubTopic: menu-updates'
reason: Ready
status: "True"
type: PubSubTopic:menu-updates
- lastTransitionTime: 2024-08-13T18:38:36.770122Z
lastUpdateTime: 0001-01-01T00:00:00Z
message: 'StorageBucket: menu-images-123456'
reason: Ready
status: "True"
type: StorageBucket:menu-images-123456
- lastTransitionTime: 2024-08-12T19:57:20.66709Z
lastUpdateTime: 0001-01-01T00:00:00Z
message: 'RunService: menu-api'
reason: Ready
status: "True"
type: RunService:menu-api
- lastTransitionTime: 2024-08-12T19:52:58.90913Z
lastUpdateTime: 0001-01-01T00:00:00Z
message: 'StorageBucket: menu-images'
reason: Ready
status: "True"
type: StorageBucket:menu-images
- lastTransitionTime: 2024-08-13T18:38:52.28648Z
lastUpdateTime: 0001-01-01T00:00:00Z
message: ""
reason: Ready
status: "True"
type: Ready
Create or Update a Resource
Workload Resources are managed through the Workload YAML. A Resource is created by adding it to a Workload YAML and applying the YAML definition to the Control Plane the same way Workloads themselves are created. Once applied, Konfigurate will manage provisioning the Resource, configuring IAM, and periodically reconciling it to prevent configuration drift. It will also orchestrate cascading dependencies where necessary, such as deploying a new Cloud Run revision to consume a newly created or updated Resource.
Note that what types of Resources you can specify on a Workload or which fields you can set may be limited based on Platform and Domain settings as well as Resource Templates.
Below is an example demonstrating how to add a Cloud SQL database to an
existing Workload using the default template. Note that if the template is
not specified using the konfig.realkinetic.com/template annotation, default
is used.
See here for more information on configuring Resources.
- YAML
- Konfigurate UI
- Konfigurate CLI
You can create or update a Resource by applying the Workload YAML definition to the Control Plane from a Workload repository.
apiVersion: konfig.realkinetic.com/v1alpha8
kind: Workload
metadata:
name: WORKLOAD_NAME
spec:
runtime:
apiVersion: run.cnrm.cloud.google.com/v1beta1
kind: RunService
metadata:
name: WORKLOAD_NAME
spec:
template:
containers:
- image: WORKLOAD_IMAGE
resources:
- apiVersion: sql.cnrm.cloud.google.com/v1beta1
kind: SQLInstance
metadata:
name: [RESOURCE NAME]
annotations:
konfig.realkinetic.com/template: default
- Navigate to the homepage of the Konfigurate UI.
- Navigate to the Platform containing the Domain for the Workload you want to add the Resource to by clicking the Platform in either the side navigation or in the main viewport.
- Navigate to the Domain containing the Workload you want to add the Resource to by clicking the Domain in either the side navigation or in the main viewport.
- Navigate to the Workload by clicking the Workload in either the side navigation or in the main viewport.
- Select the desired Environment in the Environment dropdown.
- Click the + RESOURCE button and then select the desired Resource type.
- In the Create Resource dialog, enter your Resource information (this may be constrained by templates).
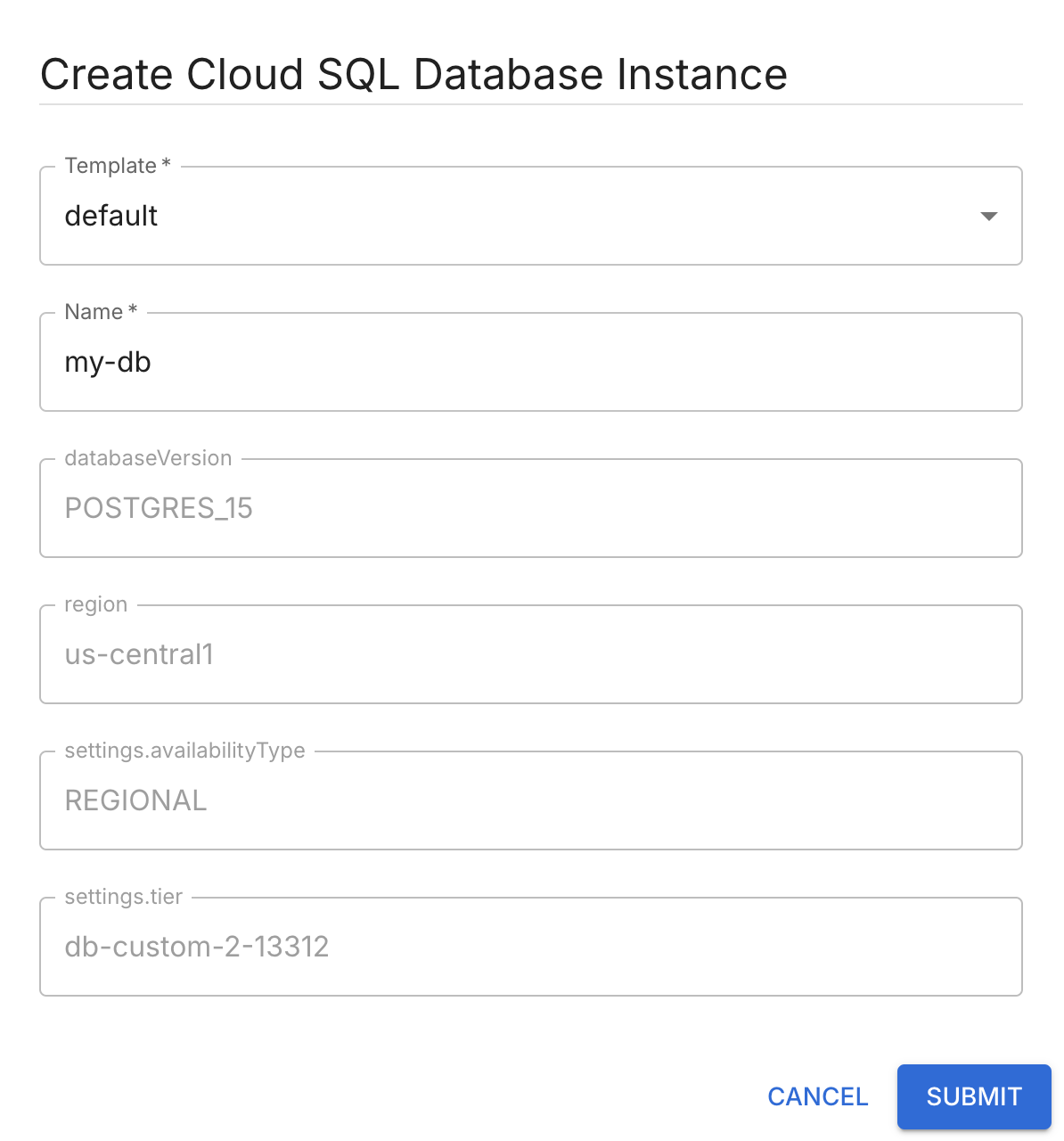
- Click SUBMIT.
- This will create a merge request in the Workload repository. Once merged, the Resource will be created.
- Ensure the Konfigurate CLI is installed and initialized.
- Run the
konfig workloads resources addcommand:
konfig workloads resources add sql [PLATFORM ID] [DOMAIN ID] [WORKLOAD ID] [RESOURCE NAME]
- This will create a merge request in the Workload repository. Once merged, the Resource will be created.
Get Resource Details
Metadata for a Workload Resource can be retrieved with the Konfigurate UI.
- Konfigurate UI
- Navigate to the homepage of the Konfigurate UI.
- Navigate to the Platform containing the Domain you want to view the Workload Resources for by clicking the Platform in either the side navigation or in the main viewport.
- Navigate to the Domain containing the Workload you want to view Resources for by clicking the Domain in either the side navigation or in the main viewport.
- Navigate to the Workload by clicking the Workload in either the side navigation or in the main viewport.
- Select the desired Environment in the Environment dropdown.
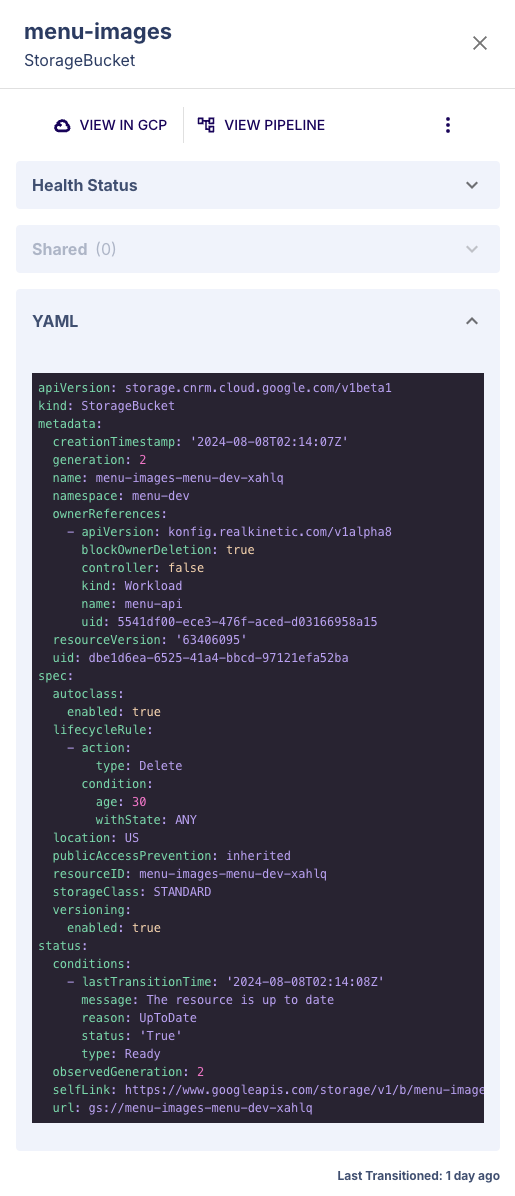
- Locate the desired Resource in the main viewport and click the status icon.
- This will expand a sidebar containing information about the Resource such as links to the Resource in GCP and the Workload's source definition, the Resource status, whether the Resource is shared with other Workloads, and the Resource's YAML applied to the Control Plane.
Workload Custom Resource Definition
- v1alpha8
| Name | Type | Description | Required |
|---|---|---|---|
| apiVersion | string | konfig.realkinetic.com/v1alpha8 | true |
| kind | string | Workload | true |
| metadata | object | Refer to the Kubernetes API documentation for the fields of the metadata field. | true |
| spec | object | true | |
| status | object | false |
Workload.spec
| Name | Type | Description | Required |
|---|---|---|---|
| resources | []object | false | |
| runtime | object | false | |
| triggers | []object | false |
Workload.spec.resources[index]
| Name | Type | Description | Required |
|---|---|---|---|
| apiVersion | string | APIVersion defines the versioned schema of this representation of an object. Servers should convert recognized schemas to the latest internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources | false |
| kind | string | Kind is a string value representing the REST resource this object represents. Servers may infer this from the endpoint the client submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds | false |
| metadata | object | false | |
| spec | object | false |
Workload.spec.runtime
| Name | Type | Description | Required |
|---|---|---|---|
| apiVersion | string | APIVersion defines the versioned schema of this representation of an object. Servers should convert recognized schemas to the latest internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources | false |
| kind | string | Kind is a string value representing the REST resource this object represents. Servers may infer this from the endpoint the client submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds | false |
| metadata | object | false | |
| spec | object | false |
Workload.spec.triggers[index]
| Name | Type | Description | Required |
|---|---|---|---|
| apiVersion | string | APIVersion defines the versioned schema of this representation of an object. Servers should convert recognized schemas to the latest internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources | false |
| kind | string | Kind is a string value representing the REST resource this object represents. Servers may infer this from the endpoint the client submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds | false |
| metadata | object | false | |
| spec | object | false |
Workload.status
| Name | Type | Description | Required |
|---|---|---|---|
| conditions | []object | Conditions represent the latest available observation of the resource's current state. | false |
Workload.status.conditions[index]
| Name | Type | Description | Required |
|---|---|---|---|
| lastTransitionTime | string | Last time the condition transitioned from one status to another. | false |
| message | string | Human-readable message indicating details about last transition. | false |
| reason | string | Unique, one-word, CamelCase reason for the condition's last transition. | false |
| status | string | Status is the status of the condition. Can be True, False, Unknown. | false |
| type | string | Type is the type of the condition. | false |