Event-Driven ETL Pipeline
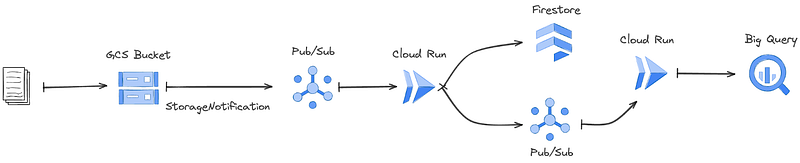
This example demonstrates implementing a serverless, event-driven ETL pipeline for GCP. Below is an architecture diagram depicting the system built. It consists of two Cloud Run Workloads, the Data Loader and the Data Transformer, and a number of associated Resources. The Data Loader is configured to receive events when new objects are written to a Cloud Storage bucket. It then fetches the newly added data from the bucket, writes it to a Firestore database, and emits a message to a Pub/Sub topic for downstream processing. This topic is then consumed by the Data Transformer service which transforms the data and writes it to a BigQuery table.
GCP Resources in Konfigurate are managed using Config Connector. Refer to the Config Connector resources documentation on how individual GCP Resources can be configured. Resource-level configuration settings can be abstracted using Resource Templates to hide resource complexity from developers and to provide standardized configuration for an organization. As you will see in the Workload YAMLs below, this example will create several different Resources including a Cloud Storage bucket, a Cloud Storage notification, Pub/Sub topics, Pub/Sub subscriptions, Cloud Run services, a Firestore database, and a BigQuery dataset.
Refer to the Workload documentation for more on the Workload YAML and configuring Resources within Workloads.
Data Loader Workload
The Data Loader Workload is a Cloud Run service which is driven by a Pub/Sub
topic subscription. The topic it subscribes to receives Cloud Storage
OBJECT_FINALIZE notifications on a bucket called etl-data-source-landing.
These OBJECT_FINALIZE notifications are emitted when new objects are written
to the bucket. The Data Loader then fetches the object from the bucket, writes
it to a Firestore collection, and publishes a message to a downstream topic.
The Workload YAML for the Data Loader is shown below. First, it configures the Workload trigger, which sets up a push-based PubSubSubscription on the specified topic. Next, the runtime configures the Workload as a Cloud Run service. Here we also set the name of the Firestore collection used by the application code as a runtime environment variable. Finally, we configure the Workload's Resources. In particular, we specify the following Resources:
- StorageBucket for our data landing zone
- PubSubTopic for the bucket notification events
- FirestoreDatabase for storing bucket data we process
- PubSubTopic for sending data downstream to the Data Transformer Workload
- StorageNotification for sending
OBJECT_FINALIZEevents to the notification topic - IAMPolicyMember binding to give the Cloud Storage agent service account permission to publish events to our topic
Konfigurate will automatically configure the correct IAM roles for the Workload's service account such that it can access the specified resources.
apiVersion: konfig.realkinetic.com/v1alpha8
kind: Workload
metadata:
name: data-loader
spec:
triggers:
- apiVersion: pubsub.cnrm.cloud.google.com/v1beta1
kind: PubSubSubscription
metadata:
name: data-loader-subscription
spec:
topicRef:
name: etl-data-source-landing-events
runtime:
apiVersion: run.cnrm.cloud.google.com/v1beta1
kind: RunService
metadata:
name: data-loader
spec:
template:
containers:
- image: data-loader
env:
- name: FIRESTORE_COLLECTION
value: loader-collection
resources:
- apiVersion: storage.cnrm.cloud.google.com/v1beta1
kind: StorageBucket
metadata:
name: etl-data-source-landing
- apiVersion: pubsub.cnrm.cloud.google.com/v1beta1
kind: PubSubTopic
metadata:
name: etl-data-source-landing-events
- apiVersion: gcp.konfig.realkinetic.com/v1alpha8
kind: FirestoreDatabase
metadata:
name: data-loader
- apiVersion: pubsub.cnrm.cloud.google.com/v1beta1
kind: PubSubTopic
metadata:
name: data-loader-events
- apiVersion: storage.cnrm.cloud.google.com/v1beta1
kind: StorageNotification
metadata:
name: data-loader-storage-notification
spec:
bucketRef:
name: etl-data-source-landing
namespace: example-domain-dev
eventTypes:
- OBJECT_FINALIZE
topicRef:
name: etl-data-source-landing-events
namespace: example-domain-dev
- apiVersion: iam.cnrm.cloud.google.com/v1beta1
kind: IAMPolicyMember
metadata:
name: data-loader-storage-notification
namespace: example-domain-dev
spec:
member: serviceAccount:service-<PROJECT_NUMBER>@gs-project-accounts.iam.gserviceaccount.com
role: roles/pubsub.publisher
resourceRef:
kind: PubSubTopic
name: etl-data-source-landing-events
Data Transformer Workload
The Data Transformer Workload is another Cloud Run service which is driven by a Pub/Sub subscription on the data-loader-events topic that the Data Loader service publishes to. It receives an event containing the Firestore document ID that was written by the Data Loader, fetches the document, performs transformations on the data, and then writes the resulting data to a BigQuery table.
The Workload YAML for the Data Transformer is shown below. Similar to the Data Loader, it sets up a Workload trigger, specifies a Cloud Run runtime with some environment variables set, and configures two Workload Resources:
- BigQueryDataset for storing transformed data
- FirestoreDatabase for retrieving the data processed by the Data Loader Workload (this database is shared between Data Loader and Data Transformer)
apiVersion: konfig.realkinetic.com/v1alpha8
kind: Workload
metadata:
name: data-transformer
spec:
triggers:
- apiVersion: pubsub.cnrm.cloud.google.com/v1beta1
kind: PubSubSubscription
metadata:
name: data-transformer-subscription
spec:
topicRef:
name: data-loader-events
runtime:
apiVersion: run.cnrm.cloud.google.com/v1beta1
kind: RunService
metadata:
name: data-transformer
spec:
template:
containers:
- env:
- name: FIRESTORE_COLLECTION
value: loader-collection
- name: BIGQUERY_TABLE_NAME
value: etl_sink
image: data-transformer
resources:
- apiVersion: bigquery.cnrm.cloud.google.com/v1beta1
kind: BigQueryDataset
metadata:
name: etl_sink_dataset
- apiVersion: gcp.konfig.realkinetic.com/v1alpha8
kind: FirestoreDatabase
metadata:
name: data-loader
annotations:
konfig.realkinetic.com/ownership_role: user
The konfig.realkinetic.com/ownership_role annotation allows a Workload to
specify the ownership type on a Resource, i.e. owner or user. This allows
Workloads to share resources, and only the owner of a Resource is allowed to
modify the Resource's configuration. See Resource
Ownership for more information.